Introduction
In October of 2019 Crunchbase raised $30M in Series C financing from OMERS Ventures. Crunchbase is charging forward, focusing more deeply on the analysis of business signals for both private and public companies. Here at the Engineering Team, we have been working on the interesting challenge of detecting these high value business signals from various sources, such as Tweets and news articles. Some examples of important signals include funding rounds, acquisitions, and key leadership hires. Finding these signals the moment they are announced empowers our customers to make well-informed business decisions.
Perhaps unsurprisingly, detecting these events automatically at scale requires machine learning models and services. Due to rapidly changing techniques, technologies and data, it is widely accepted that deploying machine learning models into production is a challenging industry task. One of the most important aspects of our architecture therefore is that it allows machine learning services to be developed independently, while keeping them integrated in a system that deploys many models both in the same and in separate micro-services.
In this post we describe our project goals, technical methodology, and architecture, serving models developed using libraries such as PyTorch alongside industry standards such as Kafka, Kubernetes, and Docker. Through our architecture we enable development of machine learning models and orchestrate their deployment.
Architecture Objectives
Important business events consist of several key pieces of information that can influence decision making. Some examples are:
- What is the event?
- Who is the event about?
- When did the event occur?
- What companies or people are affected by this event?
- Who is responsible for the event?
Several machine learning models are required to extract and interpret this information. One of the most well-known NLP (natural language processing) models is the Named Entity Recognition (NER) model. This model identifies entities in the text, such as words that represent companies and people. These entities can then be assigned roles that help us understand what these entities are doing in the text.
Of course, we aim to detect information that is relevant to Crunchbase users, so some models are used to filter out irrelevant information and segment text into appropriate categories. In this way, we can understand not only what events the text is describing, but also make sure that we understand the semantic roles of the entities in the text as well.
As we built different services to accomplish these tasks, we realized that these services could share common functionality while serving models that are distinct in their own right. In addition, models themselves can have different versions or sub-components, and downstream models could use different combinations of versions or models. For example, initially we might have a handful of models that perform several tasks, but in the future we may break models into separate pieces which can have improved or custom functionality.
Thus, we aimed to create an architecture that supported the following requirements:
- Support fast iteration and deployment for models, existing or new.
- Services should have access to different model results within the system.
- Services can easily change their model dependencies and the system handles re-deployment gracefully.
Architecture Overview
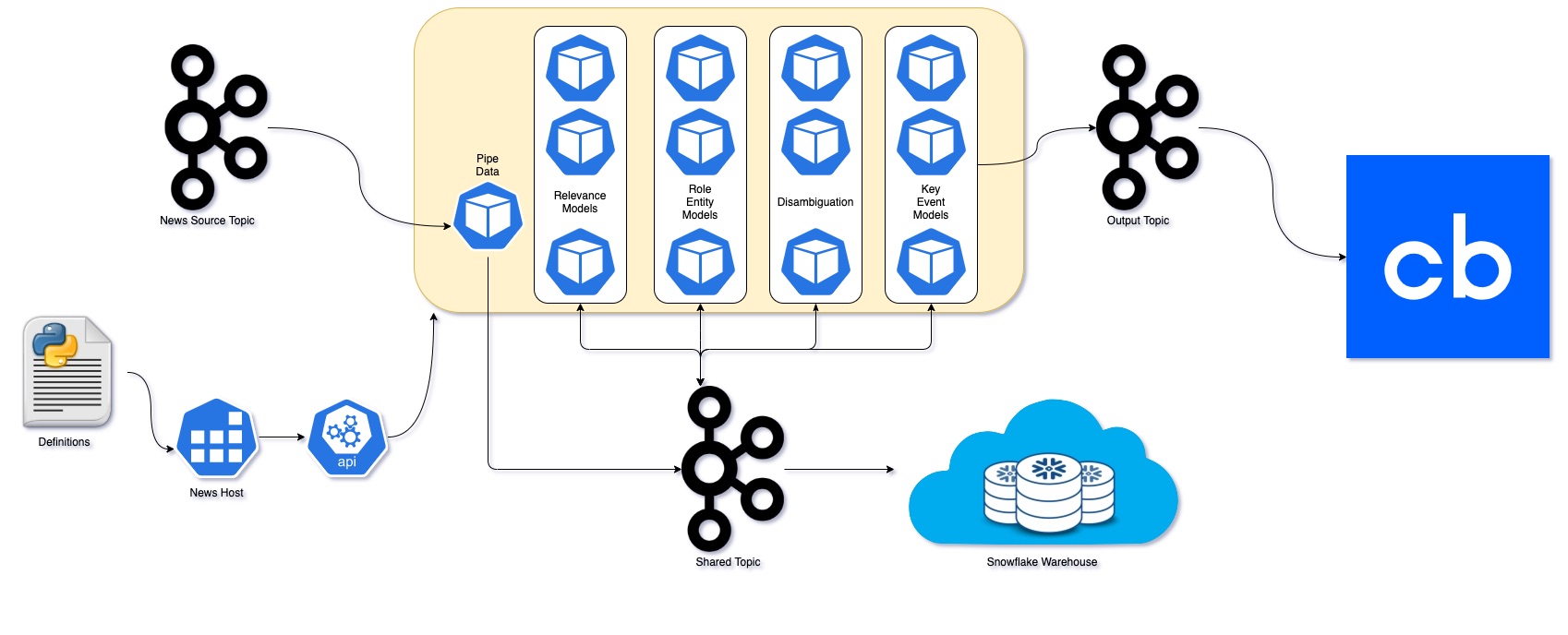
Terminology
- Annotator
- The consumer / producer service that holds the model and performs classification. May be used synonymously with classifiers.
- Central Topic
- The primary data buffer of the system, holding all of the annotator results.
- Annotations
- A data field on the Kafka topic containing the classification results from various annotators. May be used synonymously with classifications.
- News Host
- The kubernetes task taking care of spinning up/down annotators and managing their dependencies.
Infrastructure
The benefits of Kubernetes and Kafka are well-known across the industry. Kafka allows for horizontal scalability of streaming systems, allowing messages to be passed to services with high-throughput and volume.
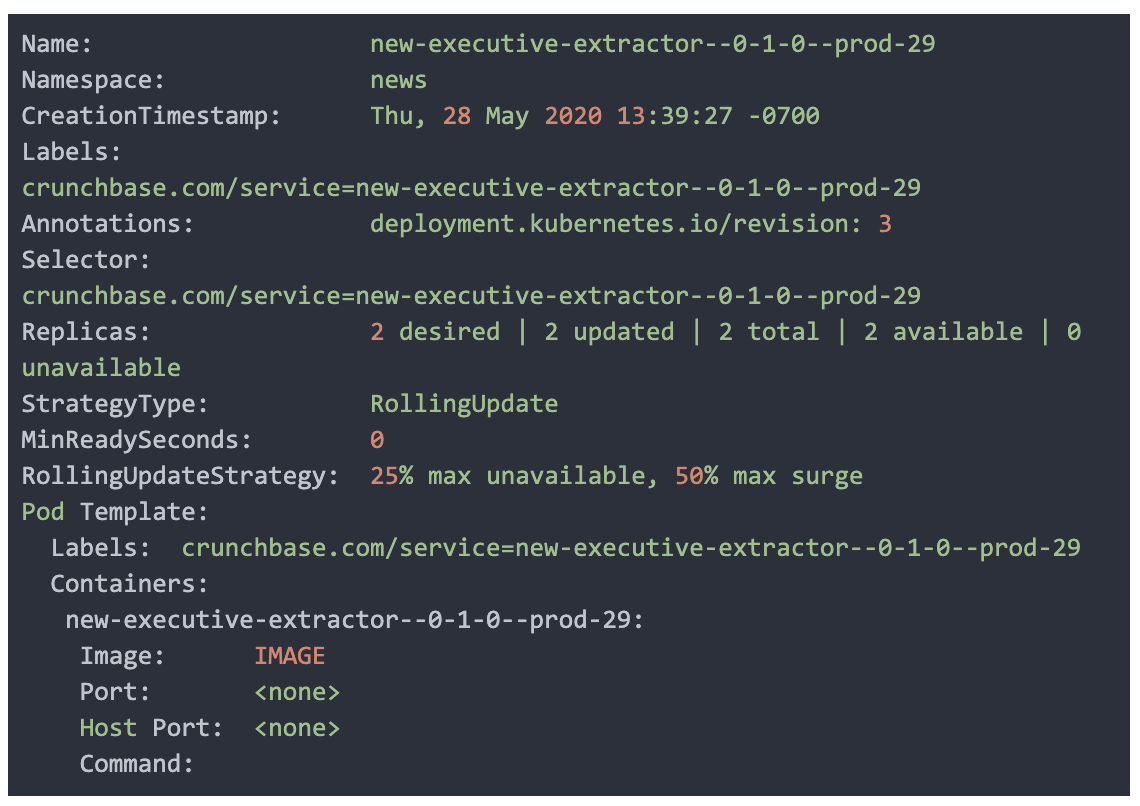
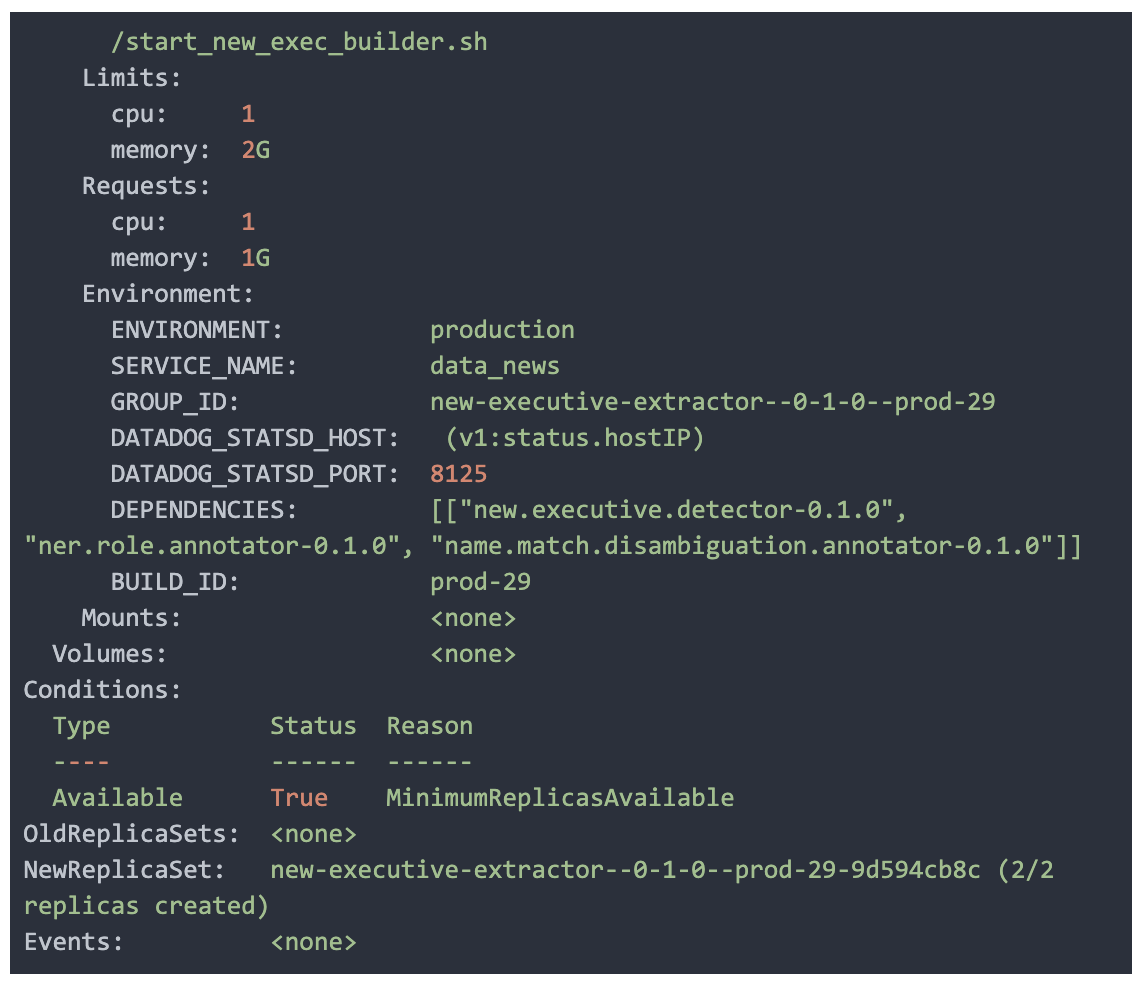
The dependencies between the annotators are defined as a DAG (Directed Acyclic Graph) inside a Kubernetes task called news host, which additionally deploys the services after the DAG definition is validated. The DAG can be defined inside Python as follows:

Once the definitions are completed, we run a test suite to validate the DAG and build a Docker image that can deploy all of the services into Kubernetes — the host service will read through the definitions and generate corresponding Kubernetes deployments on fly with a tag and dependencies.
One benefit of adding a tag on the deployment of each annotator service is that it allows us to run multiple versions of models or dependencies in parallel (multiple DAGs), such as backfill jobs or newer model DAGs. We wrote the underlying consumer / producer framework for the annotators to take into account dependency checks at the DAG deployment level before the message is delivered to the classifier logic in the service. This allows us to keep the logic for consuming and producing independent from the classification logic.
For example, the service above requires three annotations for processing: the new executive detection annotation, NER annotations, and disambiguation annotations. Only after these dependencies are met will the annotator process the message, otherwise the message is considered not ready or invalid and is ignored (the Kafka offset is incremented and we await the next message, which may have these annotation dependencies).
Thus, each annotation acts as an independent node in our graph of annotations. The dependencies (the edges) between them are handled gracefully by the underlying framework and services, ignoring messages that are not ready for annotation while tagging messages that are.
It is important to note that the annotators (the consumer / producers) are the real processors of the system. As mentioned earlier, dependency definitions are generic across the board. This allows developers to specify what input they need from other models in order to make the prediction required, allowing them to compose models without affecting every other model output. This independence between model deployments and annotation results while allowing strong interdependencies between the deployed services is a hallmark of this system design, and echoes good practices in software development as well.
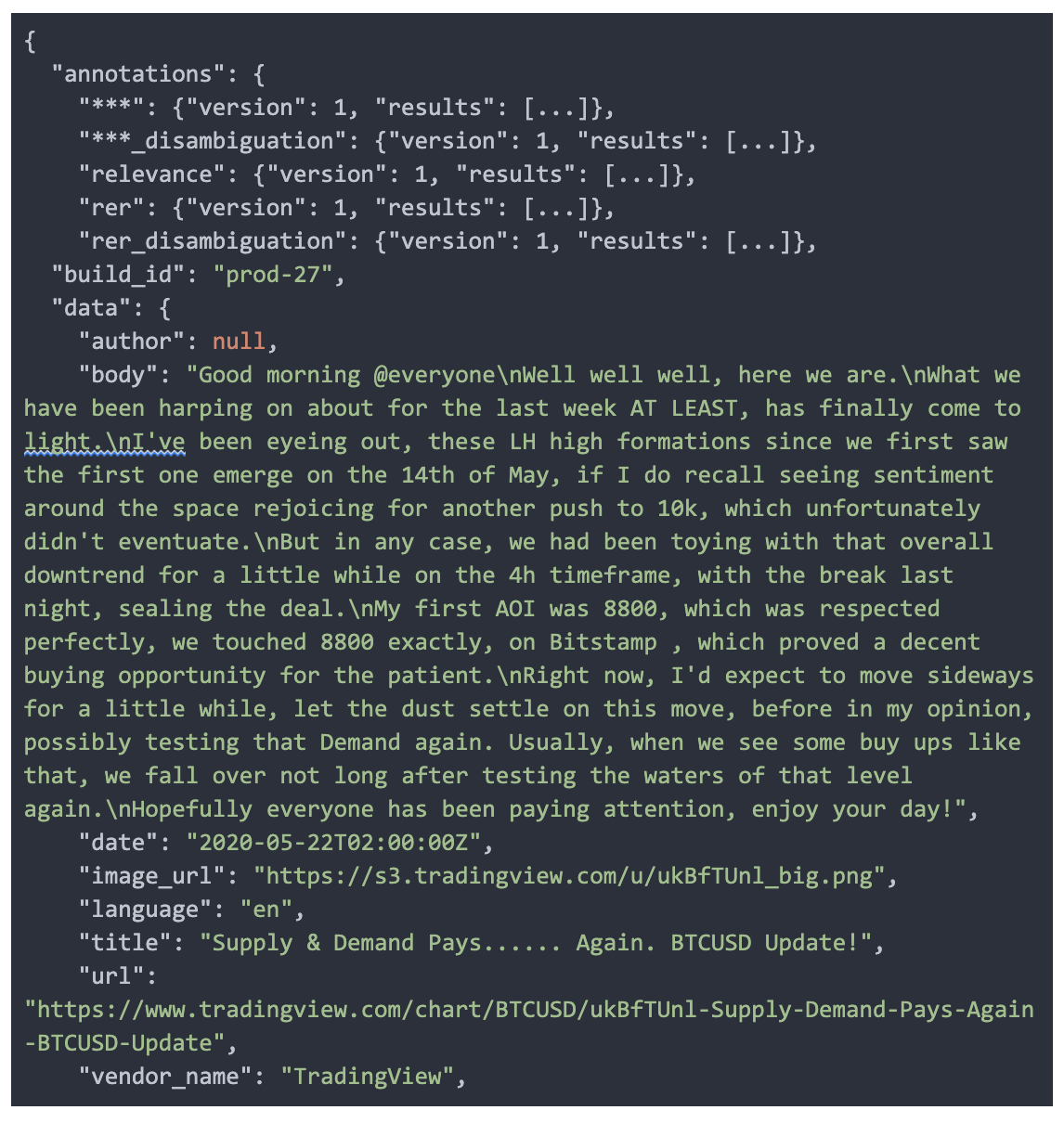
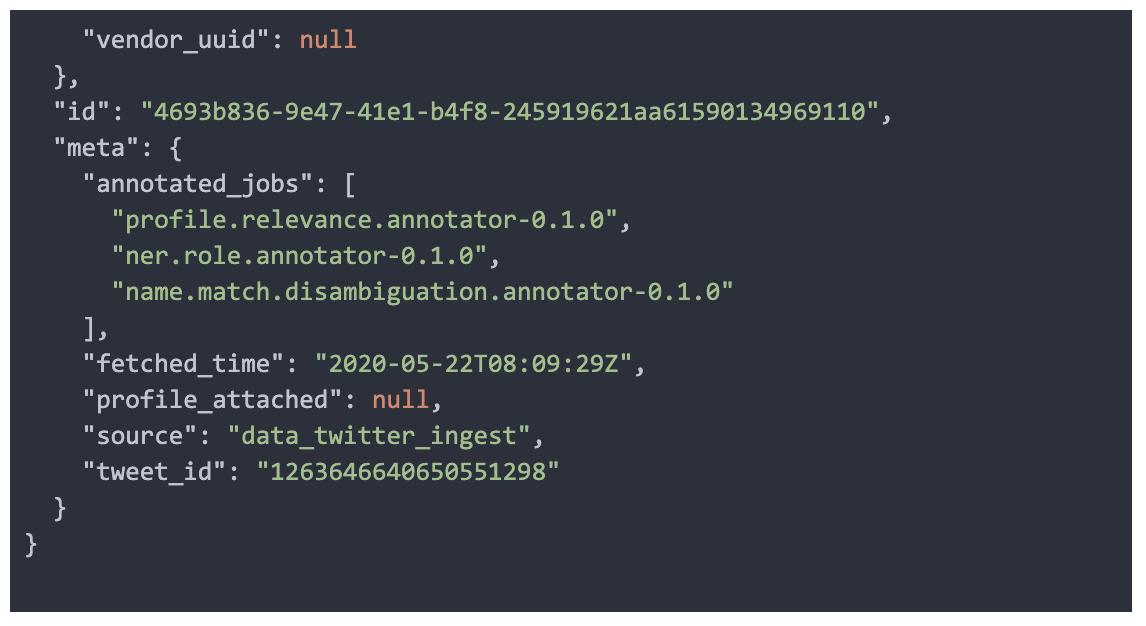
Finally, since each model annotation is recorded in the message payload, the history of all classifications is preserved within the central topic. In order to more easily enable data scientists convenient access to classification results, the topic is persisted into our data warehouse for querying and filtering by annotation type. This empowers data scientists to create more models and improve results.
Discussion
An interesting comparison for this architecture is with REST architectures. Why did we choose a streaming architecture utilizing Kafka as opposed to a set of microservices interacting via REST?
At a high level, the dependency management between a REST architecture and a consumer / producer architecture with respect to these services is functionally equivalent in terms of the DAG structure. There is no difference in this aspect, except the time at which the dependencies are resolved: In the consumer / producer model, we check dependencies of messages before the message is consumed, and message results are placed back onto the central topic buffer for consumption via other services. For REST architectures, dependencies are resolved by the service when a response is required– the other services that are needed are called and the results are composed with the logic in the service to generate a response for the top level caller.
It is worth noting that a REST API as an additional and secondary method of serving models is useful for model development purposes and internal users interested in ad hoc classification. A REST API would enable anyone internally to call a model and retrieve results without incurring the slight complexity. Given that our needs for instant model results are low in comparison to processing items for the product pipeline, we have decided to not develop this secondary method of serving models for the time being.
Furthermore, model prediction, especially for large deep learning models in a framework like PyTorch, is slow, at least compared to the commonly expected latency for most HTTP REST services. It is not reasonable for services to call a REST API and only receive a response many seconds later because downstream dependent services in the DAG are also performing their predictions at call time. Thus, we have opted to perform predictions on all relevant messages as they come in, thereby creating a more robust system for predictions and more efficiently identifying model bottlenecks through flow metrics.
Lastly, this described consumer/producer architecture facilitates fast development and fast iteration of productionized models. While REST architecture always required strict input/output, backward compatibility and strict response time(mentioned above), this architecture allows flexible model changes with proper integration tests introduced. Meanwhile, model iteration will be much easier in this architecture since REST services, in theory, need to be with 100% availability.
Future Plans
As just mentioned, we are considering creating a REST API as a secondary means of serving models to internal users for ad hoc classification while maintaining the consumer / producer architecture for processing items at scale.
We are planning to double down on news host to track each consumer’s status and be able to monitor and control them. Furthermore, we would like to support semantic versioning when resolving dependencies. This should allow us to both deploy new models faster and more easily track the performance difference between model versions.
We are happy to consider releasing an open source version of this work if enough people express interest. Please don’t hesitate to let us know at the address below!
Contact
Thank you for your interest in our work! We welcome any feedback as comments or questions; please reach out to us at team_data-insights@crunchbase.com.
Appendix
News Kafka Record Example
Kubernetes Deployment Configuration Example